
Vista
1.《Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability》
1.1 概述
这是一篇世界模型在自动驾驶领域应用的文章。世界模型可以通过历史观测与备选行动来推演未来可能的世界状态,进而评估行动的可能性,其运用有望提升自动驾驶的泛化性与安全性。
【现有的驾驶世界模型在泛化至未见环境、关键细节的预测保真度以及行动可控性以实现灵活应用方面仍存在局限】
尽管世界模型的核心前景在于实现对新环境的泛化能力,但现有驾驶世界模型仍受限于数据规模与地理覆盖范围,这些模型通常仅支持低帧率与低分辨率,导致关键细节丢失【高保真度】。此外,多数模型仅支持单一控制模态,行动可控性在未见数据集上的泛化能力研究尤为不足【泛化能力】。

本文提出Vista驾驶世界模型,一个具备高保真度与多维可控性的通用驾驶世界模型
能够以高时空分辨率预测连续且真实的未来场景
支持通过多模态行动进行灵活控制
- 可作为可泛化的奖励函数,用于评估现实世界驾驶行动的合理性
- 优于最先进的通用视频生成模型,在FID指标上超越最优驾驶世界模型55%,FVD指标提升27%
1.2 核心思想
如图所示,Vista采用两阶段训练流程
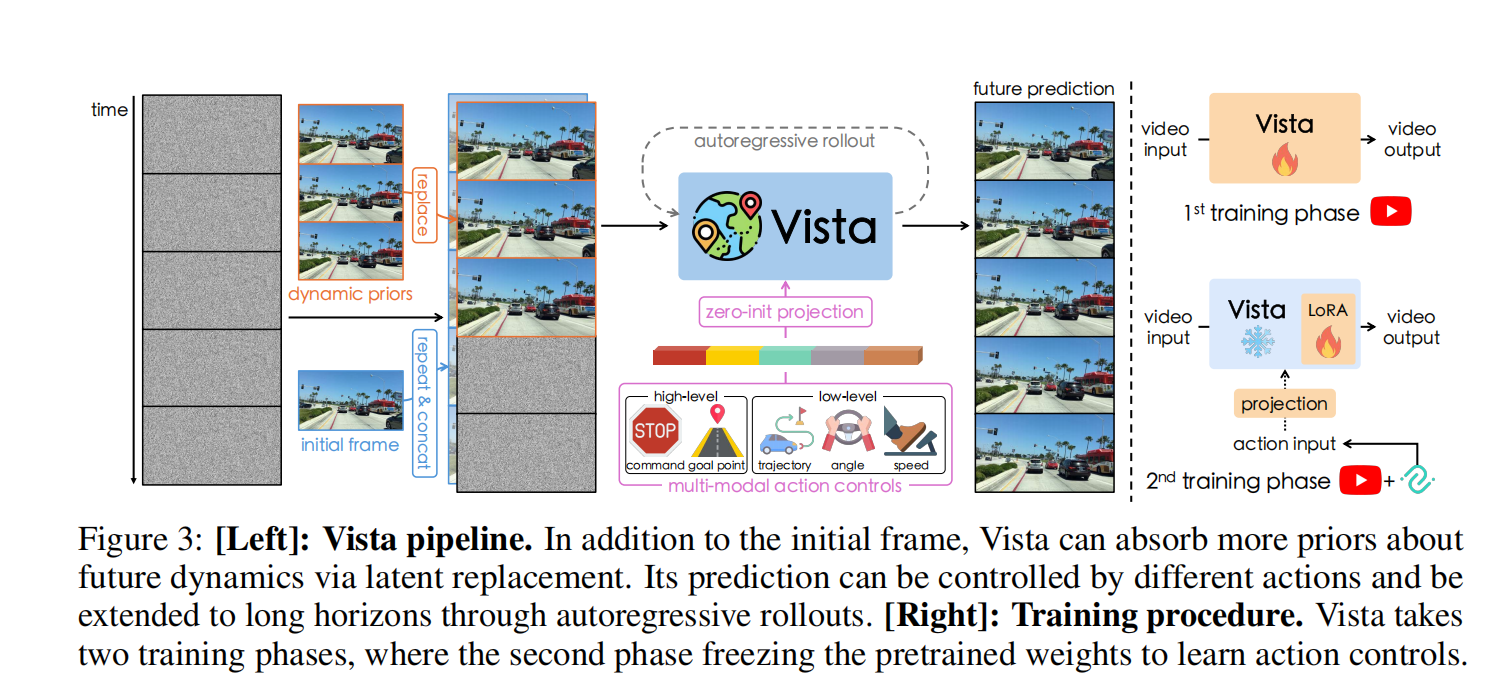
第一阶段构建专用预测模型,通过潜在替换技术实现连贯的未来预测,并采用两种新型损失函数提升预测保真度【1.2.1】。为确保模型对未见场景的泛化能力,研究者使用最大规模的公开驾驶数据集进行训练。
第二阶段引入多模态动作,通过高效协同训练策略学习动作可控性【1.2.2】
基于Vista的能力,研究者进一步提出可泛化的动作评估方法【1.2.3】
1.2.1 Learning High-Fidelity Future Prediction
Vista在扩散损失的基础上引入了两种新型损失函数:动态增强损失和结构保留损失。核心算法如下


- 动态增强损失
标准均质损失导致模型忽略关键运动,引入动态增强损失可以提升动态区域学习效率
- 结构保留损失
通过傅里叶变换分离高频细节,约束高频分量差异,防止运动导致结构退化
两种损失的引入效果如下

1.2.2 Learning Versatile Action Controllability
学习多功能动作可控性是Vista模型训练流程的第二阶段,主要关注如何使模型能够灵活响应多种动作指令,从而实现更广泛的应用场景。
- 多功能动作
传统方法通常只支持有限的动作控制,这限制了它们的灵活性和适用性。Vista模型整合了一系列多功能动作模式,包括速度和角度、轨迹、指令、目标点。
这些指令被转换为数值序列,并编码为傅里叶嵌入的统一串联形式 。这些嵌入通过学习额外的投影,扩展到UNet中交叉注意力层的输入维度,从而被模型共同学习 。
- 高效学习
Vista在第一阶段训练之后才学习动作可控性。考虑到扩散训练所需的迭代次数至关重要,动作控制学习被分为两个阶段:
第一阶段,模型在较低分辨率(320x576)下进行训练,与原始分辨率(576x1024)相比,训练吞吐量提高了3.5倍。这个阶段占据了大部分的训练迭代。
第二阶段模型在目标分辨率(576x1024)下进行短时间微调,以确保学习到的可控性能够有效适应高分辨率预测。
- 协同训练
为了同时保持泛化能力和学习可控性,Vista引入了一种协同训练策略,利用OpenDV-YouTube和nuScenes这两个数据集的样本进行训练,其中OpenDV-YouTube的动作条件被设置为零 。
1.2.3 Generalizable Reward Function
Vista模型利用其自身能力来评估驾驶行为,从而建立一个可泛化的奖励函数,而无需依赖真实的地面真值动作数据,奖励函数算法如下图所示。
1.3 总结
本文提出Vista,一个具有增强保真度和可控性的通用驾驶世界模型。Vista能够以高时空分辨率预测逼真且连续的未来场景,还具有多功能的动作可控性,并且能够泛化到未知场景。此外,它可以构建为奖励函数来评估动作。【总结】
作为一项早期探索,Vista在计算效率、质量保持和训练规模方面仍然存在一些局限。未来工作可以致力于将该方法应用于可扩展的架构。【局限和未来工作】
1.4 我的想法
这篇论文提出了一个名为Vista的通用驾驶世界模型,旨在解决现有驾驶世界模型在泛化能力、预测保真度以及动作可控性方面的局限性。本文核心亮点有1)整合大规模的OpenDV-YouTube数据集(开放世界视频日志)和nuScenes数据集(带有详细标注的驾驶场景)进行协同训练,显著增强了模型的泛化能力。2)统一处理异构的动作格式(角度、速度、轨迹、指令、目标点),并利用傅里叶嵌入和交叉注意力机制实现对多种动作的灵活控制,大大提升了模型的实用性。3)引入了新的损失函数来促进移动实例和结构信息的学习,以实现高分辨率的准确预测。
文章中很多思想和算法我不太理解其背后的数学逻辑,只理解作者的中心思想以及算法最终实现的效果。我想尝试着复现这篇文章,可是仍未成功,在Huggingface上可以找到开箱即用的模型示例,下周仍努力尝试部署下来并理解代码逻辑。
2.1 对抗攻击
2.1.1 Deepfool
由 Moosavi-Dezfooli 等人于 2016 年提出。
主要目标是寻找最小的扰动,使得深度神经网络对给定输入进行错误分类。
与一些FGSM相比,DeepFool 通常能够生成更小的、视觉上更难以察觉的扰动,从而更准确地衡量模型的鲁棒性。
核心思想是通过迭代的线性化逼近,寻找从原始输入点到深度神经网络决策边界的“最短路径”,从而产生最小的对抗性扰动。
效果如下

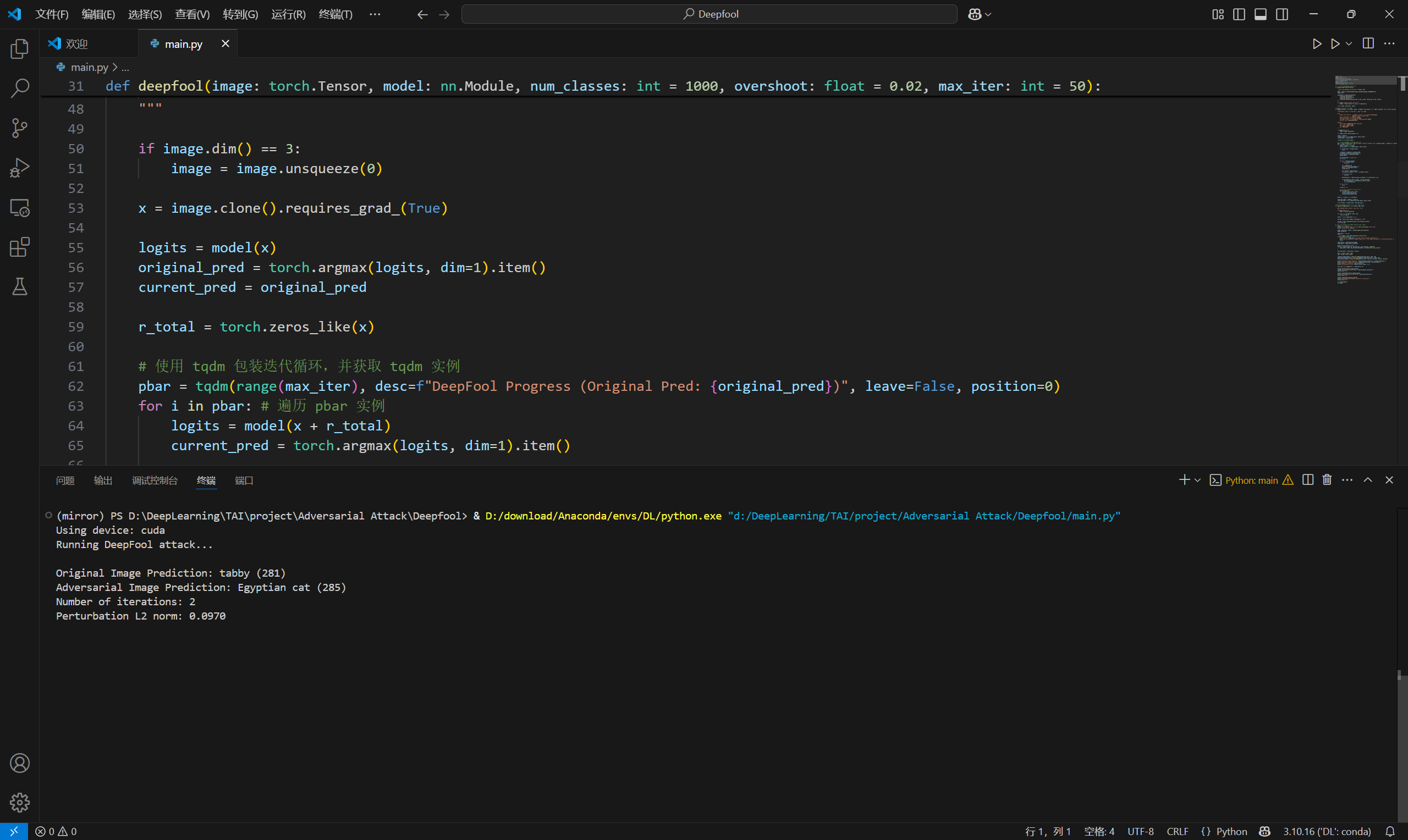
2.1.2 UAP(Universal Adversarial Perturbations)
UAP是一种单一的、微小且对人类视觉几乎不可察觉的扰动,当将其添加到来自特定数据分布的输入样本中时,能够导致深度神经网络对这些样本进行错误分类。
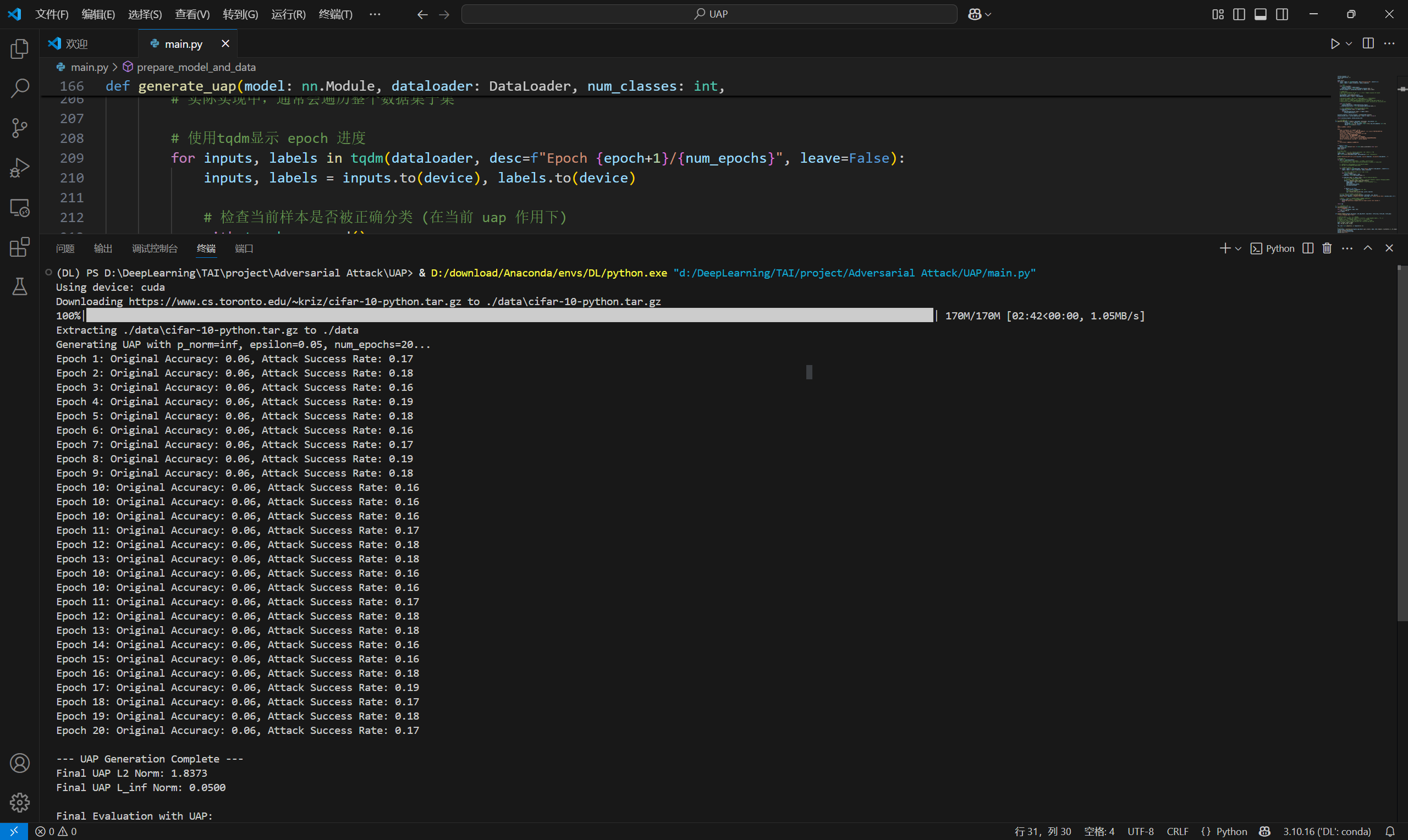
说实话,效果不太好。可能是代码逻辑有问题。
 wechat
wechat- alipay

