
WorldMem
1.《WORLDMEM: Long-term Consistent World Simulation with Memory》
1.1 概述
世界模拟通过建模虚拟环境并预测动作的后果,在自主导航、游戏引擎替代等领域具有广泛应用。
现有方法受限于有限的时序上下文窗口,难以维持长期一致性,导致场景重建时出现视角或时间跨度较大的不一致问题。
这篇论文提出了WorldMem框架,旨在解决现有世界模拟方法在3D空间长期一致性上的不足。

1.2 核心框架
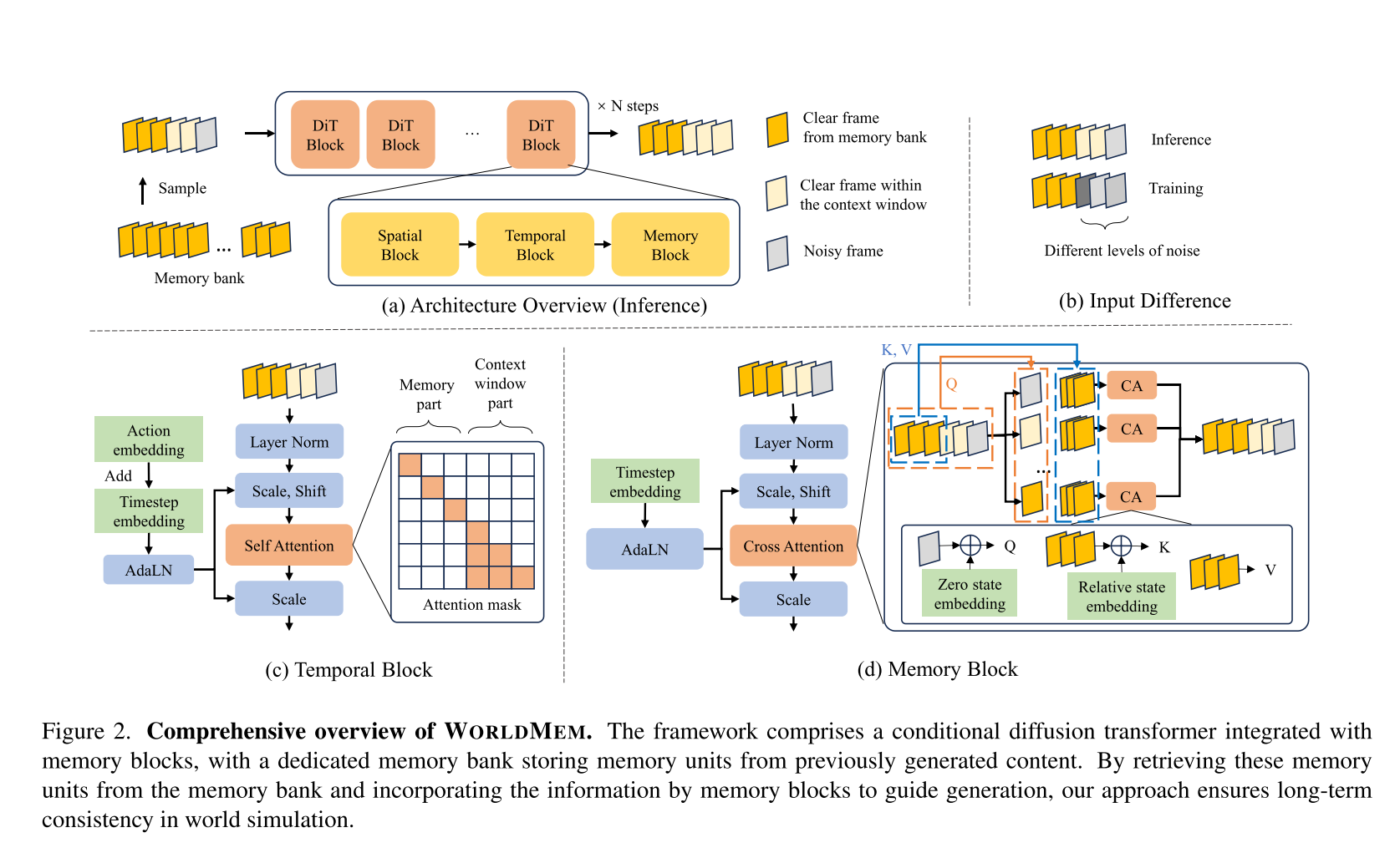
WorldMEM包含一个集成了记忆块的条件扩散变换器(Conditional Diffusion Transformer, CDiT),并有一个专用的记忆库(Memory bank),用于存储先前生成内容的记忆单元。通过从记忆库中检索这些记忆单元,并结合记忆块中的信息来指导生成,确保了世界模拟的长期一致性。
首先初始化一个Memory Bank,用于存储后续生成的记忆单元,每一个记忆单元包含三个信息:视觉帧【当前生成的场景图像】,姿态【Pose,用于表示3D空间的位置和方向】,时间戳【记录生成帧的时间顺序】。
然后模型基于DiT(Diffusion Transformer)生成每一帧,生成时输入包括三部分:噪声潜变量【当前步的噪声】、动作信号【Agent的控制指令】、时间戳【当前帧的时间信息】
根据当前帧的姿态(Pose)和时间戳,从Memory Bank中检索最相关的记忆单元,并将检索到的记忆单元注入扩散模型,经过多次【N step】扩散去除噪声,输出当前帧的高保真图像。算法流程如下

1.3 我的想法
本文提出的WorldMEM框架, 通过利用过去帧和相关状态的记忆库,解决了在世界模拟中保持长期一致性的挑战。该框架的记忆注意机制能够精确重建先前观察到的场景,并有效地模拟随时间变化的动态变化。
传统的视频扩散模型存在上下文窗口限制的问题,这篇文章提出的WorldMEM将记忆机制与扩散生成相结合,通过姿态与时间感知的注意力机制实现了长期3D一致性,使得虚拟环境能够支持复杂的交互与动态变化。
这篇文章【arXiv 2025】内容新颖,我读它是想从中学习现在主流世界模型的框架,但是很多内容涉及到我的知识盲区,我没有刻意地深入探索,仅理解该框架的大致流程和整体逻辑,很多细节如后续需要再深入探究。
2.《Revisiting Feature Prediction for Learning Visual Representations from Video》
Meta 首席人工智能科学家 Yann LeCun 提出了一种新的架构JEPA,通过联合嵌入预测架构,在自监督学习中实现了高效、高语义的表征学习。Meta AI

这篇文章提出了V-JEPA(Video-Joint-Embedding Predictive Architecture)框架,是一种视频联合嵌入预测架构模型,通过自监督学习方法,预测抽象表示空间中视频的缺失部分。
2.1 核心思想
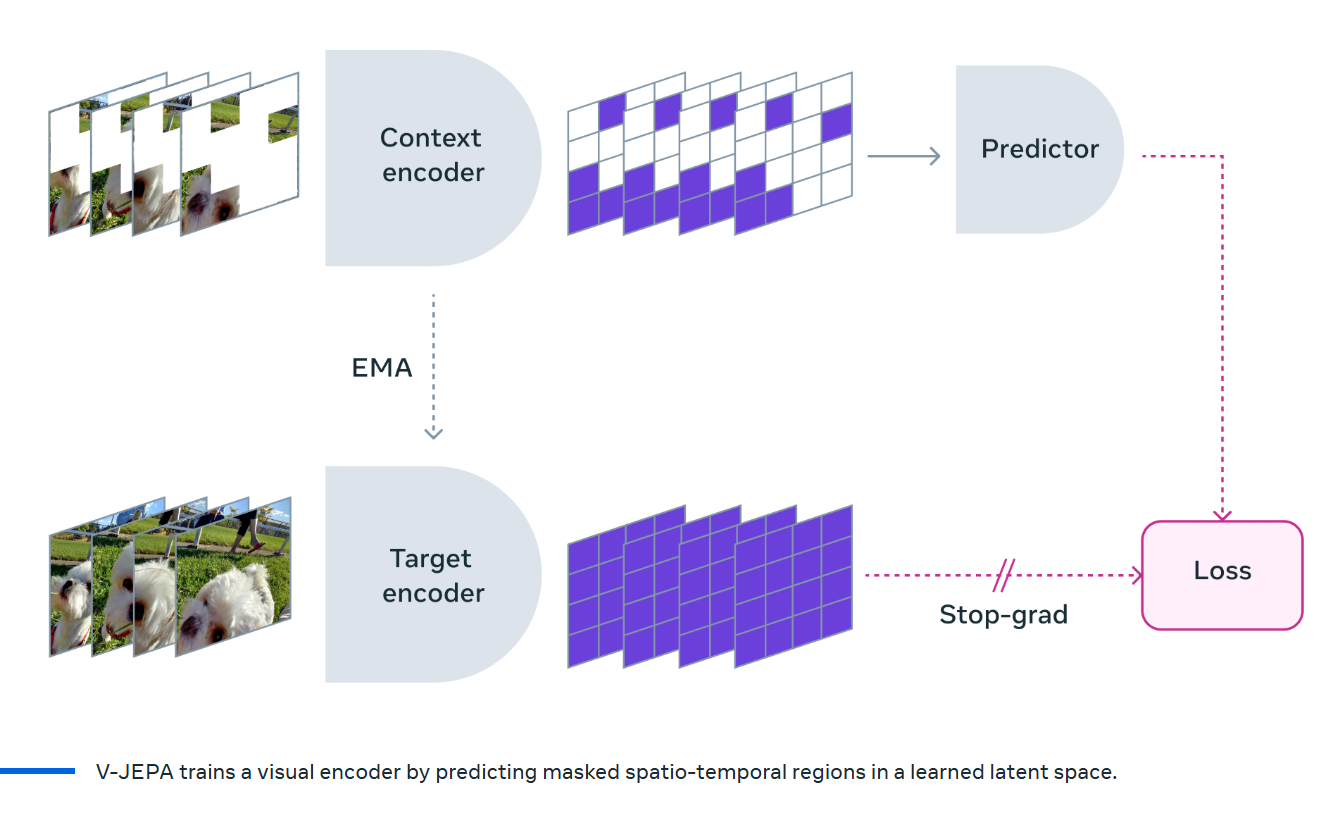
V-JEPA中有三个核心组件:上下文编码器(Context encoder)、预测器(Predictor)、目标编码器(Target encoder)构成。
其核心思想是通过随机采样抽取视频中的连续帧,并将这些连续帧进行遮掩,被遮掩的部分即为被预测的目标块,遮掩后的部分即为保留下来的上下文。需要注意的是这里的遮掩并不是像素级的遮掩,而是嵌入级的遮掩,是对图像编码后的嵌入空间进行遮掩,以此让模型学习更抽象的表征。
- 上下文编码器
上下文编码器用于处理上下文块,生成上下文块的嵌入。
- target encoder
目标编码器用于生成目标块的嵌入,参数通过上下文编码器的指数移动平均更新【EMA,Exponential Moving Average,一种平滑参数更新策略,目标编码器参数变化缓慢,避免与上下文编码器同步快速更新导致模型崩溃】(可以理解为一种更平滑的参数更新方法)
- predictor
预测器是基于上下文嵌入和位置标记,预测目标块的嵌入。
- loss
预测嵌入与目标嵌入的L2距离,优化上下文编码器和预测器参数,目标编码器通过EMA更新。
2.2 我的想法
JEPA的核心思想非常简洁,通过精心设计上下文块和目标块,以及上下文编码器、目标编码器和预测器,通过减少预测器的表征与目标编码器的表征之间的差异,从嵌入空间而非像素空间的层面学习更抽象的表征。
V-JEPA的思想与I-JEPA非常相似,区别在于前者是针对视频遮掩部分的预测,后者是图像遮掩部分预测,但是本质上都是图像的预测。
JEPA架构归为世界模型的类别,世界模型旨在学习外部世界抽象的内在表征,通过对过去的观察和潜在的动作来模拟和预测未来,与JEPA从单个上下文块预测同一图像中多个目标块的表示,学习抽象语义特征表示非常相似。
3.PGD
PGD攻击(Projected Gradient Descent,投影梯度下降)是一种白盒对抗攻击方法,常用于生成能够欺骗神经网络模型的对抗样本。
算法思想如下

可以理解为PGD攻击是多次迭代FGSM,并将结果投影到合理的范围。
受到 I-JEPA 的启发,我尝试采用ViT模型将图像编码,再沿着梯度上生的方向生成对抗样本,结果如下


与上周尝试的FGSM不同,本次实验是在CIFAR-10数据集上测试,图像从单通道的手写数字变成了多通道的RGB图片,且攻击轮数从一轮变成了多轮。
该实验旨在了解对抗样本的生成方法,学习如何用pytorch实现深层神经网络。
下周将系统地调研对抗样本生成与使用场景,并结合代码深入理解对抗样本攻击的效果,在去基地之前打好基础,争取暑假可以快速上手科研之路。
 wechat
wechat- alipay

