
World Models
1.《World Models》
传统强化学习中,智能体通常通过试错与环境交互来学习策略。然而,这种方法面临高维输入处理和信用分配(Credit Assignment)两大难题。
本文提出构建世界模型,通过无监督学习压缩环境的时空特征,使智能体能在“梦境”(dream,我的理解是模型生成的虚拟场景)中训练,从而降低对真实环境的依赖。
通过将世界模型中提取的特征作为Agent的输入,训练出一个策略来解决所需的任务。甚至可以完全在由其世界模型生成的虚拟场景中训练Agent,并将该策略迁移回实际环境。
1.1 模型框架
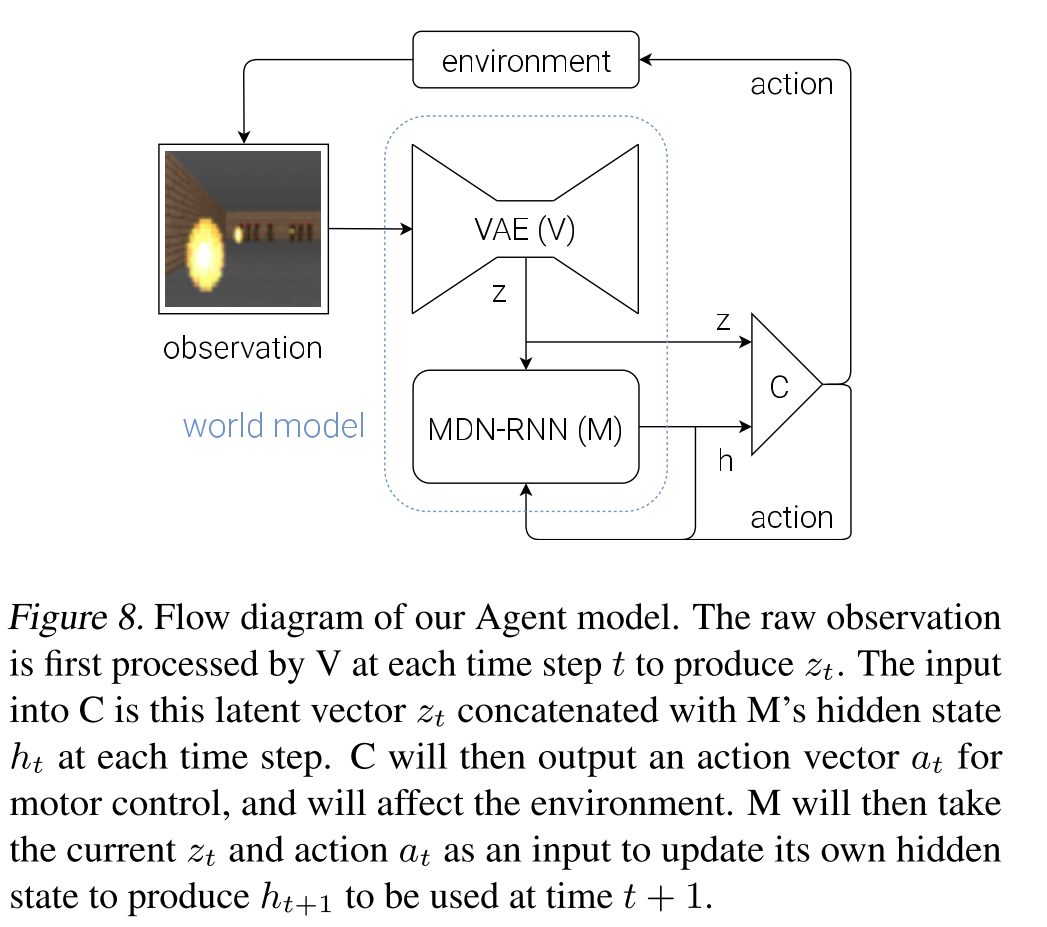
本文提出一个智能体框架,该智能体包括视觉感知组件(Vison Model),记忆组件(Memory Model)和决策组件(Controller Model)
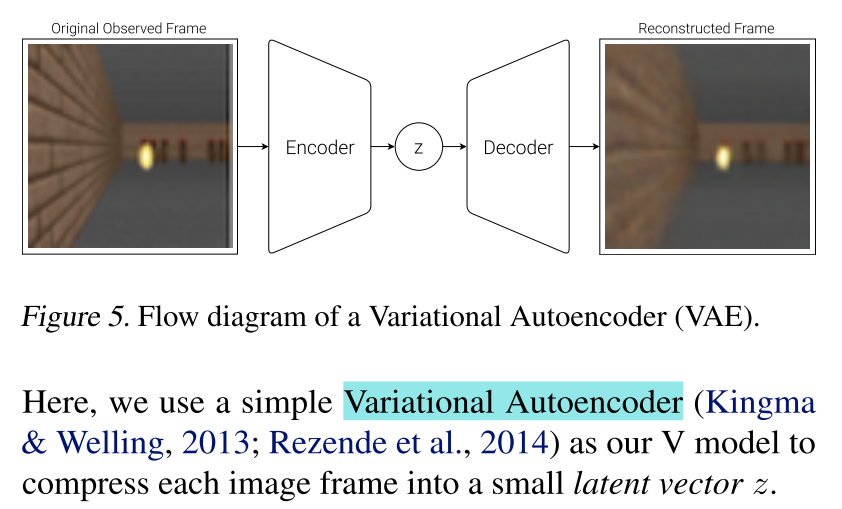
VAE Model(V)
视觉组件是由变分自动编码器(Variational Autoencoder)构成,可以将输入的图像压缩成潜在向量$z_t$
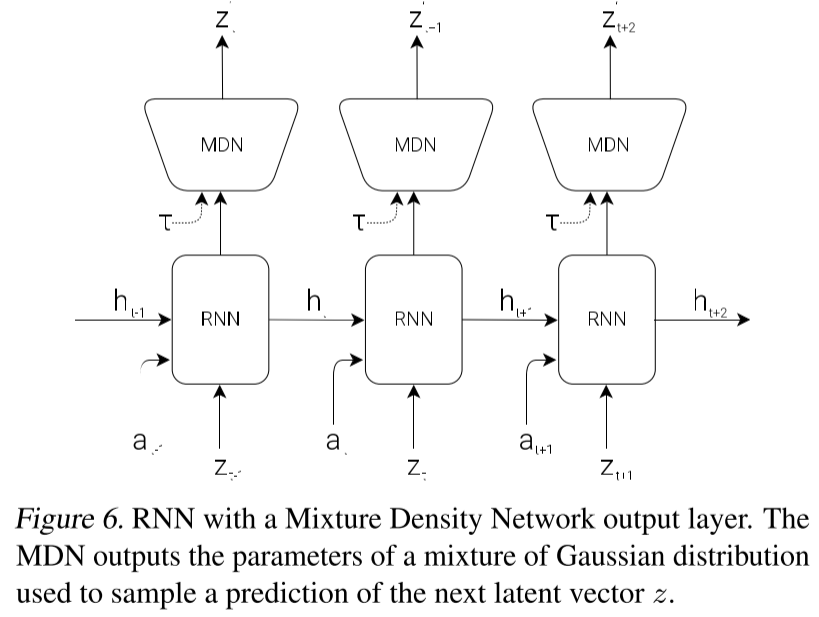
- MDN-RNN Model (M)
记忆组件是由具有混合密度网络(Mixture Density Network)输出层的RNN构成,基于当前状态的输入和过去的信息输出下一时间状态的预测向量$z_{t+1}$,这里输出的是一个概率密度分布$p(z)$,而不是特定的预测$z$
- Controller Model(C)
决策组件是由一个简单的层线性模型构成,将当前时间状态的$z_t$和$h_t$作为输入,输出为当前决策$a_t$。决策组件负责确定要采取的行动方案,以便在环境部署期间最大化Agent的预期累积奖励。

1.2 实验
1.2.1 CarRacing-v0任务
一个预测型的世界模型可以提取现实世界中有用的空间和时间表征,通过将这些特征作为决策组件(Controller)的输入,我们可以训练一个控制器来执行连续控制任务。
本文的第一个实验是在一个自上而下的赛车环境,学习通过像素输入进行驾驶。流程如下

1.2.2 VizDoom: Take Cover任务
在虚拟的场景中训练agent得到的决策,可以迁移到现实世界中。
本文的第二个实验是训练智能体在由其世界模型生成的幻觉中学习,该幻觉是经过训练以模拟 Viz-Doom 环境的,Agent学会躲避攻击。流程如下

1.3 我的想法
我的调研思路是从World Models出发,了解世界模型的组成和结构,再从组成部分分析可能存在的攻击方法。所以从世界模型的开山鼻祖David Ha提出的World Models开始,但是我发现一个很大的问题,这篇2018年提出的世界模型在当时很先进的方法放在现在似乎不太适用,比如本文中世界模型Vison Model组成之一采用VAE(Variational Autoencoder)2D图片向量化,是否可以采用ViT的方式处理图像,将二维图像转换为适合Transformer处理的序列输入。此外本文采用MDN-RNN(RNN with a Mixture Density Network)通过隐藏状态传递信息,但是RNN采用门控单元保留或丢弃过去信息,现在主流的方式是基于Transformer的自注意力机制建立序列中两个位置的关联。所以这篇文章提出了一个通过无监督学习压缩环境的时空特征,训练智能体对环境的决策,但是可能与目前主流的世界模型有一定差别。
我的任务是调研针对世界模型的攻击方法,所以我想转变一下思路,从当前主流的世界模型出发,先从小型的、通用的世界模型推理入手,再针对世界模型的组件(比如世界模型可能涉及到多模态大模型,是否可以对多模态的与训练编码器进行攻击)进行攻击方式的调研。
2.DreamerV3
项目地址 https://github.com/danijar/dreamerv3
上周阅读AdvDreamer是针对Dreamer(世界模型的一种)进行对抗性攻击,所以我尝试从Dreamer入手,想理清Dreamer的模型架构。
遇到的问题汇总
1.该项目适用于Linux and Mac测试,不建议在Windows系统测试。(出现了文件编码无法解读的问题,于是我尝试一台Linux服务器)
2.cuda版本与显卡驱动要严格一致(服务器显卡驱动支持的最高cuda版本是11.6,而我安装的cuda版本是11.8,后面尝试重装cuda后依旧报错)
3.库冲突(这个问题依旧没有解决)
由于项目暂时跑不通,我下周尝试调研当前世界模型中最通用的模型并部署。
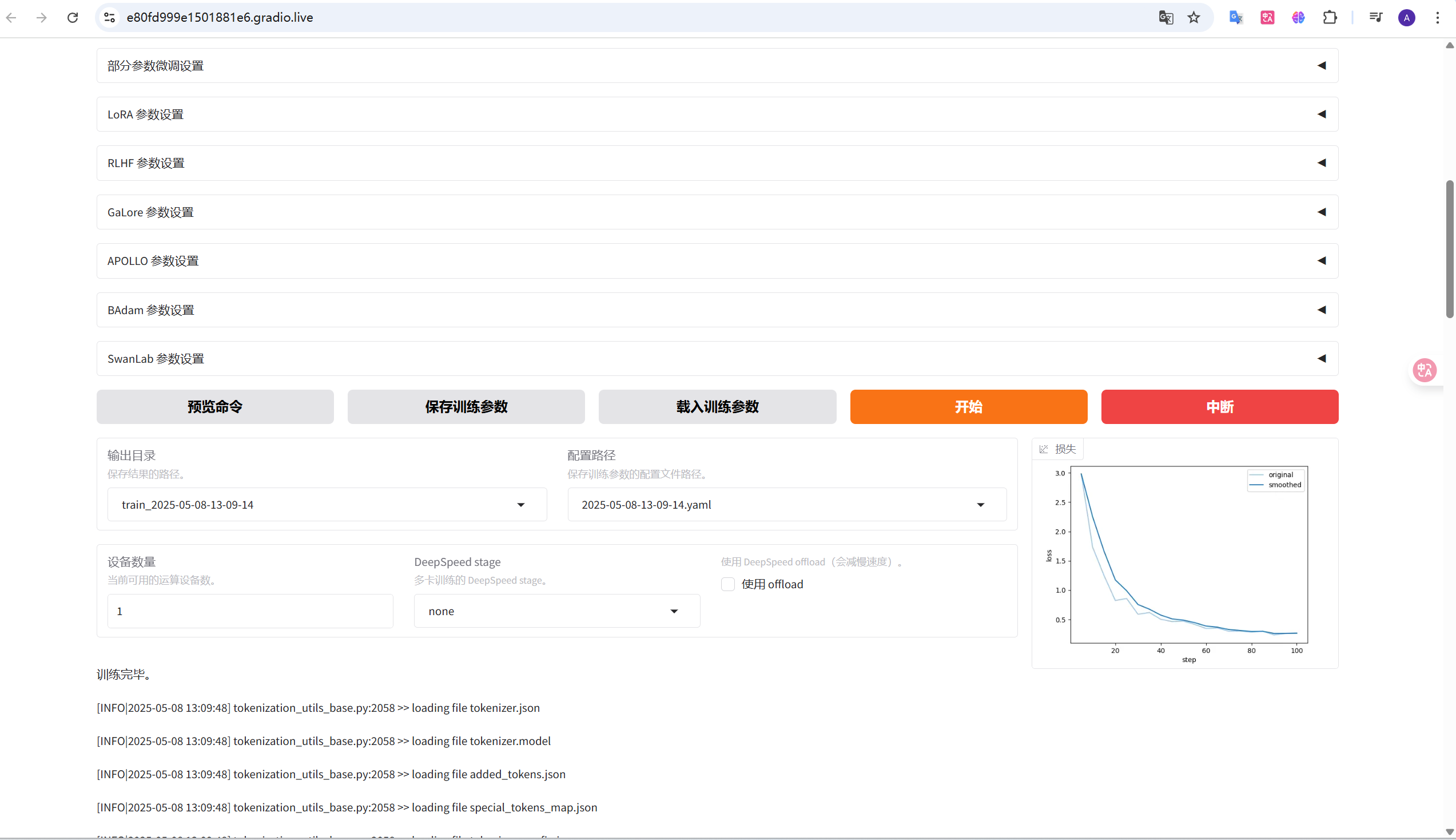
3. LLama微调
由于周四前没有任务(呃呃呃,我一定提高积极性,以后学会自主调研和探究,不要push一下做一下),周一到周三探索了一下Lora方法微调大模型,属于兴趣拓展。开会后明确了目标,针对世界模型进行攻击。
 wechat
wechat- alipay

