
AdvEncoder
1.《Downstream-agnostic Adversarial Examples》
1.1 概述
自监督学习通常使用大量没有标签的数据训练一个预训练编码器,它是一个通用的特征提取器,这样下游的使用者就可以微调这个预训练编码器实现一系列的下游任务。
本文基于预训练编码器提出一个可以生成下游不可知对抗样本的框架AdvEncoder,旨在为一系列自然图片构造通用的对抗性扰动或补丁,使其能欺骗所有的继承了受害编码器的下游任务。
与传统对抗性样本工作不同,预训练编码器的输出是特征矩阵而不是分类标签。因此,实验者首先提取图片中高频成分(high frequency components,HFC),然后设计了一个生成式攻击框架,通过学习数据的分布构建对抗性扰动或补丁。
实验结果表明,在预训练数据集或下游数据集不可知的情况下,该对抗样本可以成功攻击下任务。实验者采用四种防御策略减缓攻击,结果进一步证明AdvEncoder攻击的可能性。
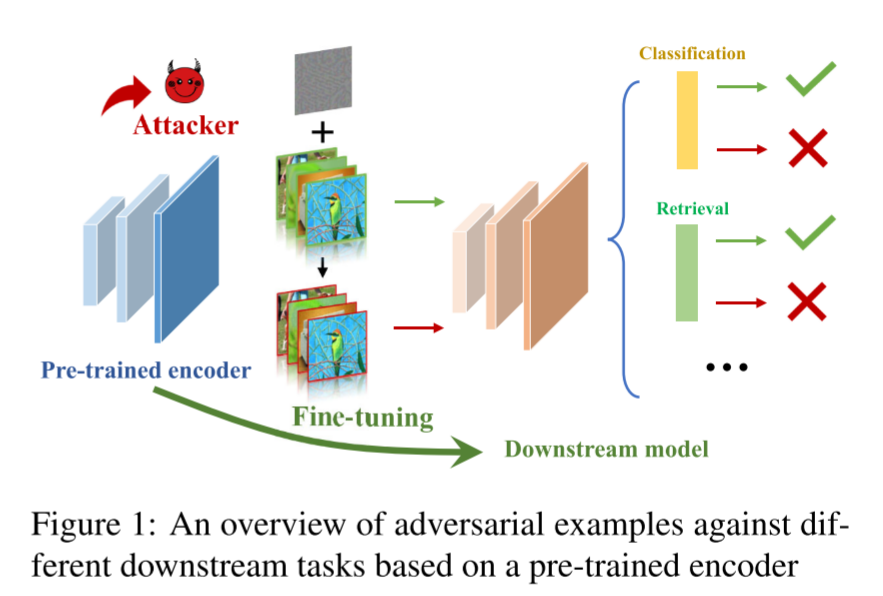
- 利用一个高频成分提取器获取良性样本和对抗样本的HFC,并且使二者之间的距离拉远以影响到模型决策
- 设计一个生成式对抗框架AdvEncoder,输入一个固定的随机噪声,通过学习数据据分布构建对抗性扰动和补丁
1.2 背景和相关工作
自监督学习的模式可以分为对比学习方法、无负样本方法、基于聚类方法、基于冗余减少方法,这些方法网络结构不同,对对抗性攻击的防御能力也不同。
对预训练编码器的攻击方式包括成员推理攻击、模型提取、后门攻击、投毒攻击等,往往发生在训练阶段,而对抗性样本发生在测试阶段。PAP(Pre-trained adversarial perturbations)通过提升低层特征激活产生对抗性样本,缺少语义且极度依赖预训练数据集,实验者可以在更严格的情况下直接改变样本的组织结构特征构造更有效的对抗性样本。
已有的工作分为基于优化的对抗性攻击和生成式对抗攻击,后者可以产生更一般性的、更自然的对抗性样本。生成式对抗性攻击需要模型输出的标签信息,而预训练编码器输出的是对应图片的特征矩阵,故已有的方法无法直接运用到预训练编码器。
抵御对抗性样本的方法有数据预处理、对抗性训练、剪枝、微调。
1.3 方法论
1.3.1 挑战
- 在预训练编码器中缺少监督信号
预训练编码器输出的是图片对应的特征矩阵而不是标签,使得传统对抗性样本攻击预训练编码器是不可行的。
仅仅在图片上增加一个很大的扰动也无法达到使预训练编码器分类错误的目标,因为这样只是在相同的类中移动了小距离,而不是使对抗性样本远离原来的方向移动。
实验者提出使用通用的对抗性噪声,改变图片的高频成分(HFC),以此影响预训练编码器的输出。这是从直接改变图片语义的方面,将目标样本推离原来的决策边界。
- 缺少下游任务的信息
从预训练编码器到下游任务的范式中,微调会模型原来的特征边界,以上方法仅仅欺骗了预训练编码器而对下游任务决策几乎没有影响,如图2(b)对抗性样本已经离开了原来的类,但是在微调导致的决策边界的变化后再一次准备下游模型正确分类。
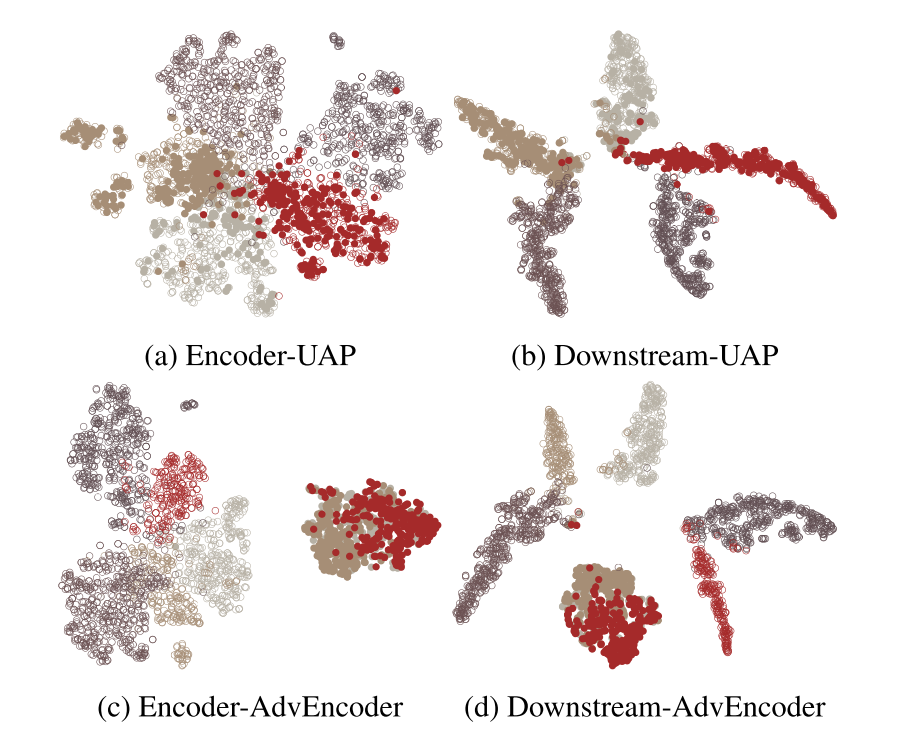
实验者设计了一个生成式攻击框架,提高了对抗性噪声的一般性,使所有的目标样本在特征空间聚类在一起并且远离所有的正常样本,使下游模型很难正确地分类目标样本。
1.3.2 基于频率的生成式攻击框架
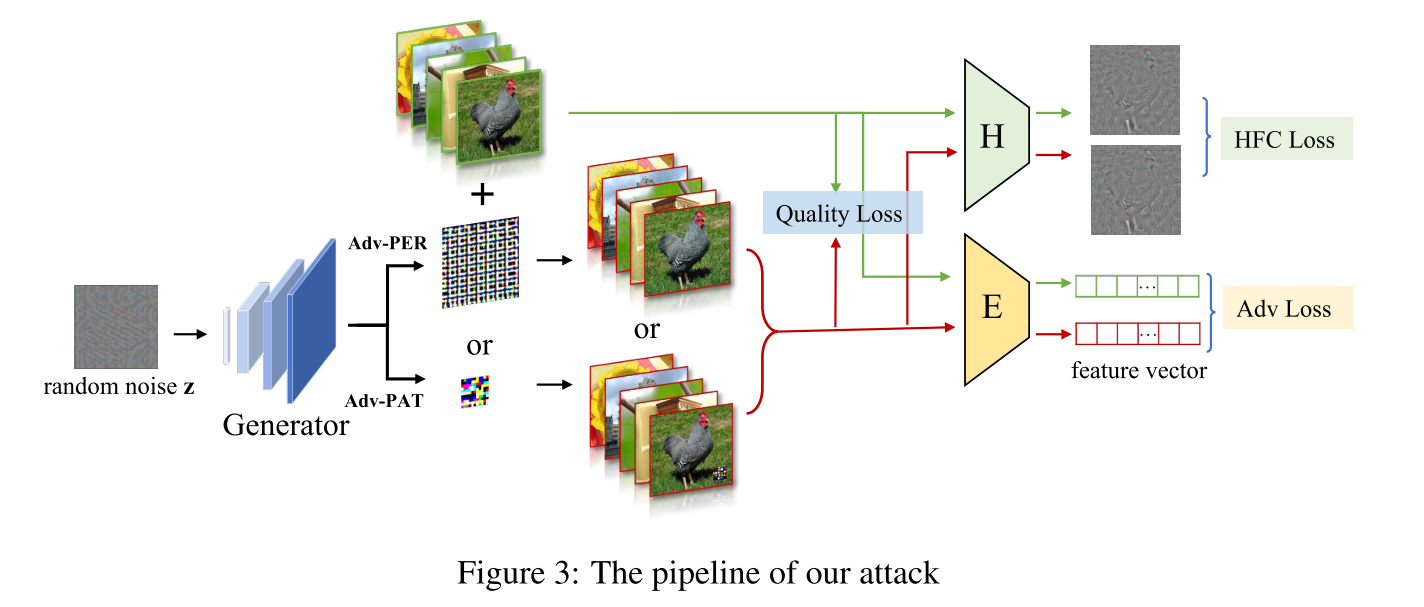
实验者提出一个针对预训练编码器的生成式攻击框架AdvEncoder,它包含一个生成器(Generator,G),一个高频提取器(High frequency filter,H),一个受害编码器(victim encoder,$\varepsilon $)
将一个固定的噪声输入到生成器,可以获取到一个通用的噪声,将其附在攻击者替换的数据集的目标图片上从而获得通用性对抗样本。
核心算法如下

$L_{adv}$代表对抗性损失函数,通过最大化正常样本与对抗性样本在特征矩阵中的距离提高对抗性噪声的攻击能力。采取InfoNCE损失测量预训练编码器的输出特征矩阵之间的相似度。

$L{hfc}$代表高频成分损失函数,$L{hfc}$通过调整高频组成成分改变图片原有的语义特征,进一步使目标样本远离当前位置。
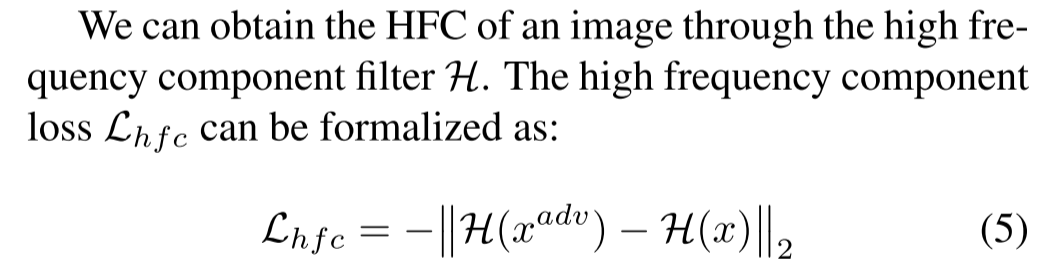
$L_q$代表品质损失函数,控制对抗性噪声的大小。

AdvEncoder将通用对抗性噪声转换成两种攻击形式,通用对抗性扰动(AdvEncoder-Perturbation, Adv-PER)和通用对抗性噪声(AdvEncoder-Patch, Adv-PAT)
- Adv-PER
攻击者直接将由生成器产生的对抗性扰动加在图片上
$x^{adv}=x+G(z)$
- Adv-PAT
攻击者将对抗性补丁应用在图片中的某个随机位置处

1.4 我的想法
本文提出了一种构造下游不可知对抗性样本的框架AdvEncoder,可以同时生成对抗性扰动和对抗性样本,并验证了其在下游任务上的攻击表现,强调针对预训练编码器的新的防御机制的必要性。
有意思的一点是第二篇文章是关于用对抗性样本攻击多模态模型的预训练编码器,可见对抗性样本对预训练编码器的危害性。更有意思的是第三篇文章提出安全微调预训练编码器来防御对抗性样本的方法,文中也提到了AdvEncoder的表现,与UAP(Universal Adversarial Examples)相比AdvEncoder在下游不可知的情况下表现更好,但是通过安全微调预训练编码器可以有效抵抗AdvEncoder的攻击。有点世界上最锋利的矛和世界上最坚固的盾相抗衡,颇有意思。
读完这篇文章,我有一些疑问待日后继续深入研究,1)AdvEncoder的高频特征提取器是如何工作的,2)自监督学习中预训练编码器是如何工作的,3)其他的攻击方式如成员推理攻击、模型提取、投毒攻击、后门攻击是如何实现的,与对抗性样本攻击的区别有哪些,4)常见的防御机制如数据预处理、对抗性训练、剪裁、微调是如何实现的
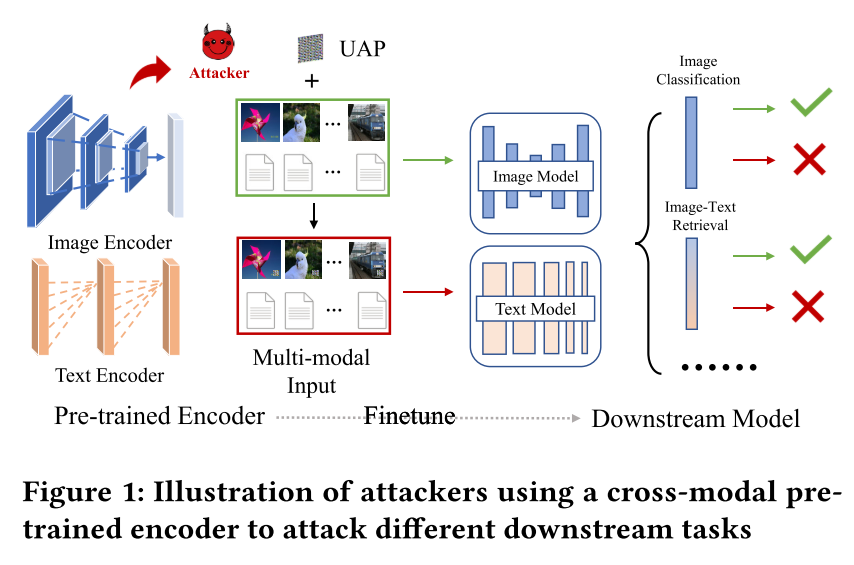
2.《AdvCLIP: Downstream-agnostic Adversarial Examples in Multimodal Contrastive Learning》
2.1 概述
多模态对比学习在大量原生的、无标签的成对图文数据上训练一种通用的特征提取器,这个特征提取器使各种复杂的下游任务大大受益。
本文提出一种基于跨模态预训练编码器的生成下游不可知对抗性样本的框架AdvCLIP,旨在为一系列自然图片构建一种通用的补丁,以此欺骗继承了受害跨模态预训练编码器的所有下游任务。
实验者首先建立了一个拓扑图来捕捉目标样本和他们邻居之间的相对位置,然后设计了一个基于拓扑偏移的生成式对抗网络来生成一个通用对抗性补丁。通过将补丁加在图片中,实验者最小化它们与不同模态的嵌入相似度,并扰乱了特征空间中的样本分布,以此实现无目标攻击。
实验结果表明AdvCLIP在八种训练集上的训练的两种下游任务上的杰出攻击表现。实验者也采取了三种常用的防御方式缓解AdvCLIP,结果进一步证明针对跨模态预训练编码器的新型防御机制的必要性。
- 建立拓扑图结构捕捉样本之间的相似度
- 摧毁同一样本在不同模态之间的映射关系,以及多样本之间的拓扑关系
- 使对抗性样本不仅仅是跨越决策边界,而是远离原来的类
2.2 相关工作
现有的VLP(Vision-Language Pre-trained)模型可以分为两类,基于交叉编码的方式和基于嵌入的方法。前者采用基于Transformer的交叉注意力机制计算不同模态间数据的相似度,后者分别将不同模态的数据编码成视觉和文本的表示,并且通过计算来自不同模态的数据之间的特征距离来测量跨模态的相似度。本文主要研究后者中CLIP的安全性。
通用的基于图片的对抗性攻击有两种形式,扰动和补丁。前者通过在图片全局加入视觉上不可察觉的噪声欺骗模型,后者在图片一个小的区域加上一个对抗性补丁。基于补丁的方法在现实场景中可应用型更强,本文主要关注对抗性补丁。
PAP(Pre-trained adversarial perturbations)通过提升低层特征激活产生对抗性样本,Co-Attack采用协作损失函数来避免由图片和文本模态同时攻击造成的矛盾,但是它只考虑了简单的白盒场景来产生对抗性样本。本文针对下游任务实现有效的无目标的攻击。
2.3 方法论
2.3.1 挑战
- 图片和文本之间的模态间隔
由于复杂的高维特征空间和多模态数据之间的异质性,仅仅最大化嵌入之间的距离可能无法成功欺骗模型。
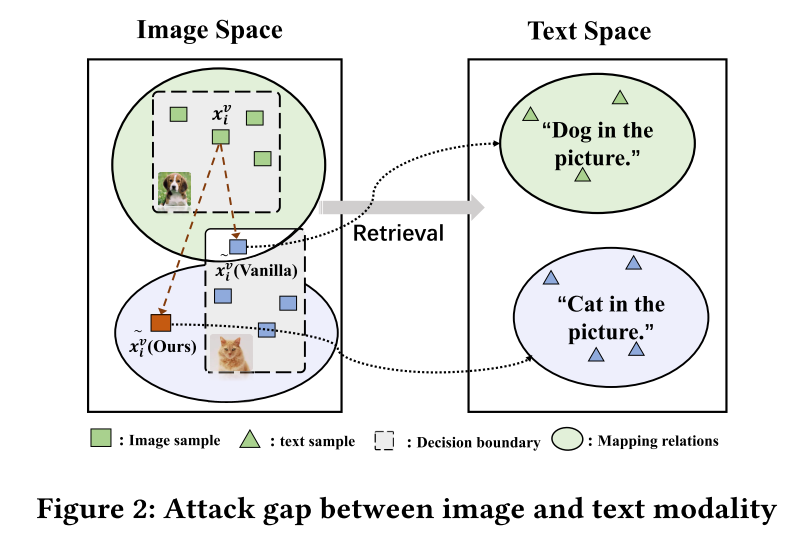
实验者考虑摧毁样本最邻近的关系,通过将特征空间中有序的样本变得无序增强攻击效果。实验者分别为对抗性和良性嵌入建立拓扑来测量对应样本之间的相关性,这个拓扑是基于样本在特征空间的相似度建立的邻里关系图确定。邻里关系图中边的权重是两个不同样本是邻居的概率,拓扑结构的偏移是通过扭曲两个图的概率分布来实现的。
- 跨模态预训练编码器与下游任务之间的转移
微调跨模态预训练编码器使得模型的特征空间的边界改变,可能导致已有的攻击失效。
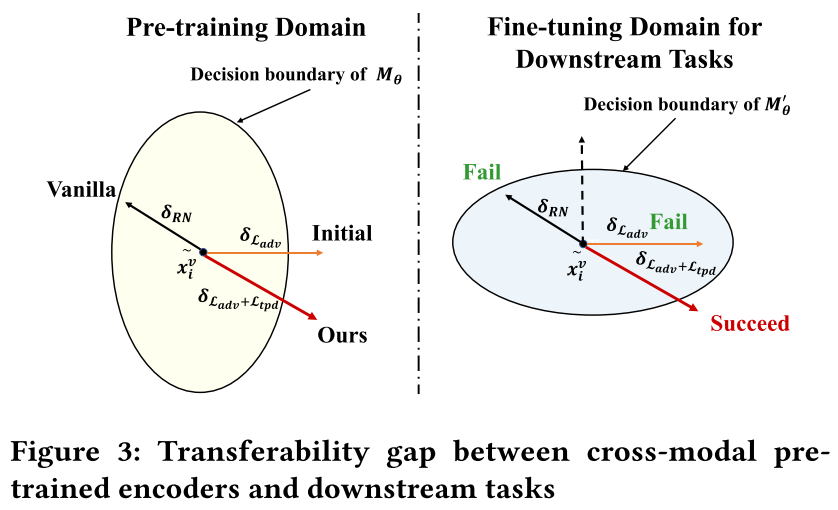
实验者设计了一个生成式对抗网络生成有很强共性的对抗性噪声,以至于对抗性样本远离原来的分类而不仅仅是跨越决策边界。
2.3.2 基于拓扑偏移的生成式攻击框架
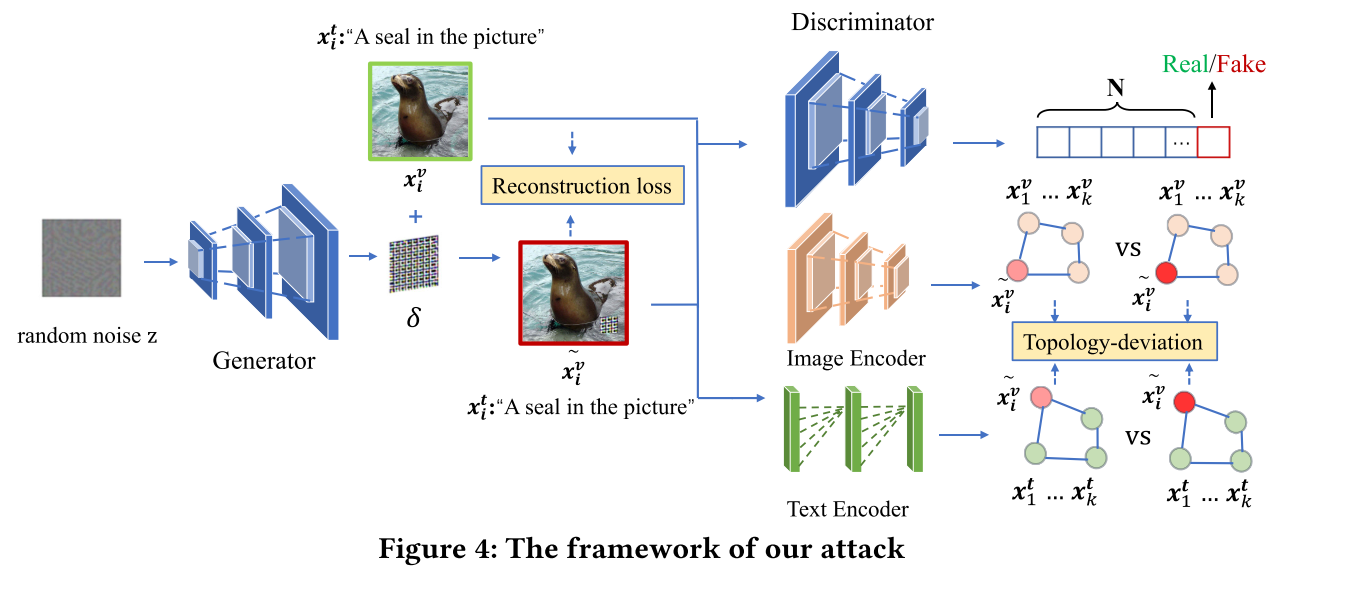
实验者针对跨模态的预训练编码器提出了一个生成式攻击框架AdvCLIP,它包含一个对抗性生成器(Generator,G),一个鉴别器(Discriminator,D),一个受害的跨模态预训练编码器(victim cross-modal encoder,M),这个预训练编码器包含图片编码器($E_v$)和文本编码器($E_t$)
将一个随机噪声输入到对抗性生成器,生成一个对抗性补丁,将其应用在图片的某个特定区域得到对抗性样本,由此欺骗下游任务。
核心算法

$L_{adv}$代表对抗性损失函数,用于使目标样本偏移特征位置,通过在图片上加入补丁使得对抗性样本的特征矩阵 $E_v(\widetilde{x_i^v} )$ 同时远离原来的图片特征矩阵和干净的文本特征矩阵

$L_{tpd}$代表拓扑偏移损失函数,通过使对抗性样本的图片特征矩阵同时与良性样本的图片特征矩阵和文本特征矩阵偏移,最大化它们之间的拓扑距离。
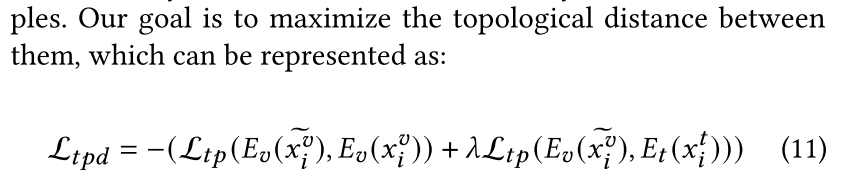
$L_q$代表品质损失函数,控制对抗性噪声的大小。
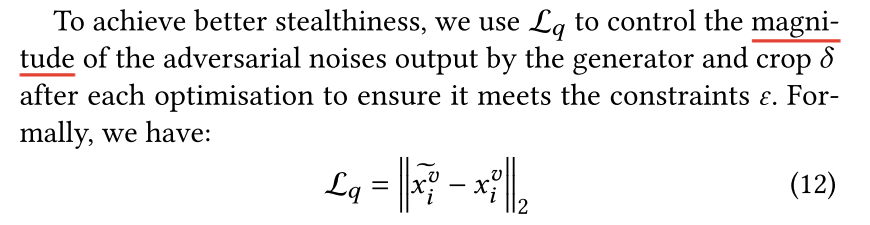
$L_{gan}$使得对抗性样本看起来更自然,自然图片与添加补丁的对抗性样本在鉴别器中倾向于一致。

2.4 我的想法
本文基于多模态对比学习中跨模态预训练编码器构建下游不可知对抗性样本的攻击框架AdvCLIP,通过基于拓扑偏移的生成式对抗性网络产生一个通用的补丁以欺骗下游任务,并验证了AdvCLIP在八种训练集训练的两类下游任务上的杰出攻击表现,强调针对预训练编码器的新型防御机制的重要性。
感觉这一篇的思想与设计与第一篇极其相似,都是通过生成器生成对抗性样本,不同点在于 1)AdvEncoder可以生成对抗性扰动和对抗性补丁,AdvCLIP聚焦于生成对抗性补丁 2)AdvEncoder运用于自监督学习的预训练编码器,AdvCLIP运用于多模态的预训练编码器 3)AdvEncoder是设计了一个高频特征提取器,针对图像中的高频组成成分(HFC)改变图片原有的语义特征,使目标样本远离当前位置,而AdvCLIP是根据邻里关系图构建拓扑,通过使对抗性样本的图片特征矩阵同时与良性样本的图片特征矩阵和文本特征矩阵偏移,使对抗性样本远离原类别。
读完这篇文章,我有一些疑问待日后继续深入研究,1)多模态的预训练编码器是如何工作的 2)多模态模型的工作机制是什么 3)InfoNCE损失、余弦距离损失
3.《Securely Fine-tuning Pre-trained Encoders Against Adversarial Examples》
3.1 概述
本文深入调研已有的预训练范式之内的对抗性样本的防御机制,结果表明当前防御措施的失败源于预训练数据和下游任务之间的域转换,以及编码器参数的敏感性。
本文提出了一个两步对抗性微调的方法Genetic Evolution-Nurtured Adversarial Fine-tuning(Gen-AF),旨在提高下游模型的鲁棒性。Gen-AF首先采取基因导向双轨制对抗性微调策略来有效继承预训练编码器,然后评估每一层的鲁棒敏感性并创建一个字典,top-k层的鲁棒冗余层被挑选出来且余下的层保持固定。实验者基于进化适应性的微调方法进一步提高了模型的泛化能力。
在十种自监督训练方法和六种数据集上的实验结果表明,Gen-AF有很高的测试准确率和较强的鲁棒性,同时实现了鲁棒性和泛化能力的较好平衡。
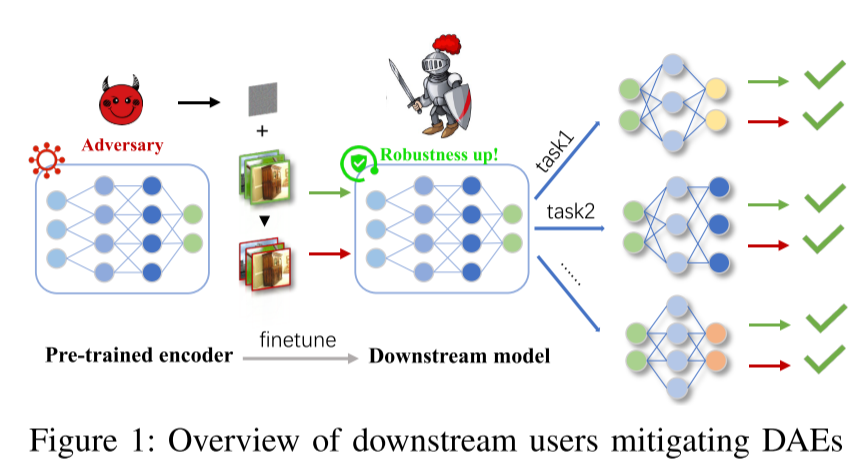
- 目标是提高下游模型的鲁棒性,同时保留预训练编码器的泛化能力
- 采用双层优化协作策略,分别优化预训练编码器和分类器的参数,对预训练编码器采取小的学习率,对分类器采取标准的学习率
- 采用基因正则化维持自然样本在表示空间的相对位置关系,因此保持了模型固有的泛化能力
- 对下游模型的每一层建立一个敏感度字典,选择前k层鲁棒性较低层,固定其余的鲁棒性敏感层。对选择的层采取标准的微调训练提高下游模型整体的泛化能力
3.2 核心算法
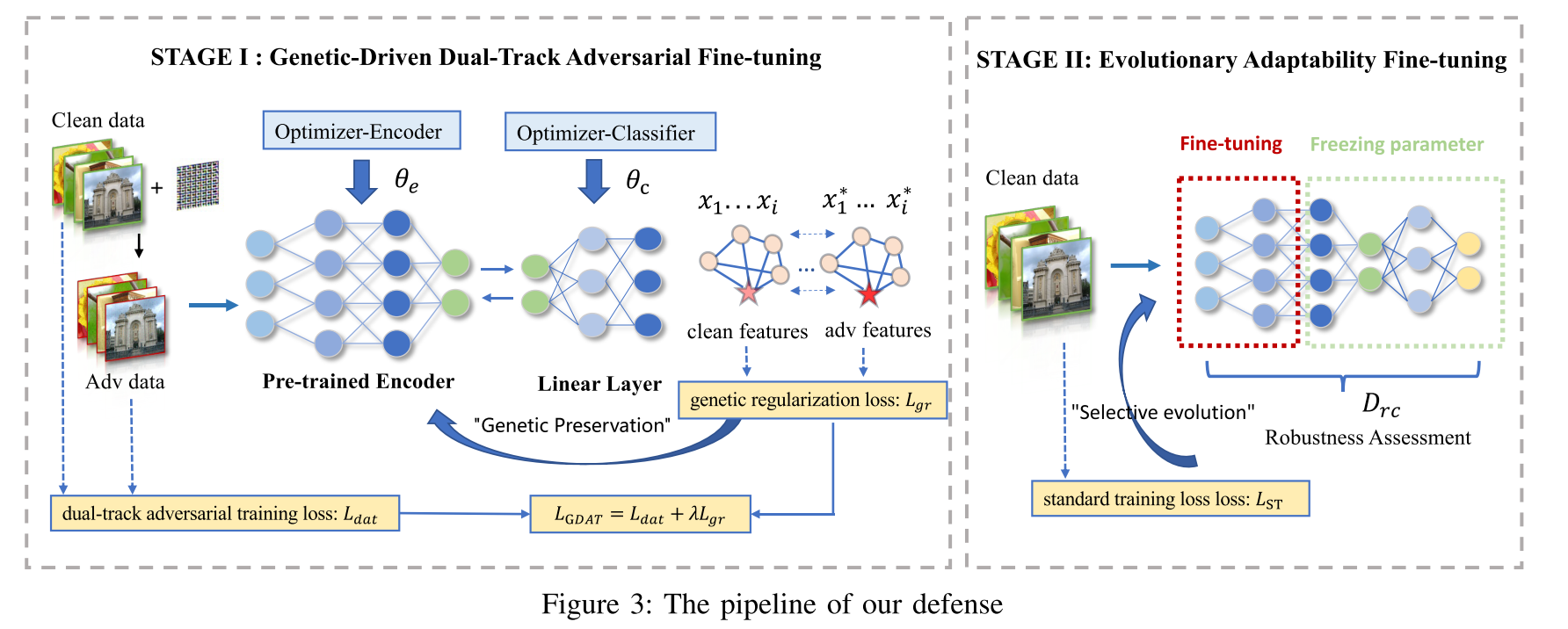
第一阶段:基因驱使的双轨制对抗性微调
实验者设计了一个基因正则化损失来限制对抗性样本和良性样本在特征空间的偏移,从而避免了预训练编码器固有知识的损失。

首先构建一个图 G 来描述特征空间中对抗样本和良性样本之间的拓扑关系,通过限制差异性来保留预训练模型中的遗传信息,从而有效地适应新的数据领域。
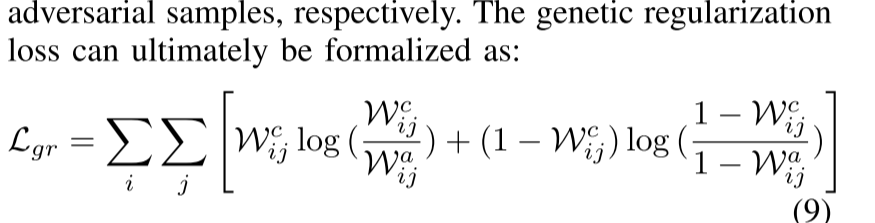
实验者进一步提出了一种双层优化器协作策略,分别优化预训练编码器和分类器的参数,从而增强对抗微调过程的稳定性和效率。
 第二阶段:进化适应性的微调
第二阶段:进化适应性的微调
实验者集中于冗余基因以提高初始模型的泛化能力
首先计算模型每一层对于对抗性噪音的敏感度并创建敏感度字典

然后选择较低鲁棒性的前k层,并通过微调这些冗余层以提高模型的泛化能力。

核心算法流程如下

3.3 我的想法
本文提出一种基因进化培育对抗性微调方法Gen-AF,首先使用双层优化器策略和基因正则化进行对抗性训练,增强模型的鲁棒性同时保持其固有的知识。然后集中于进化适应性微调,对冗余层微调以提高模型的泛化能力。Gen-AF在五种最先进的通用对抗性攻击上表现出杰出的防御能力。
本文提出了防御对抗性样本攻击的方法,基于前两篇文章的学习,Gen-AF方法是否也可以用在多模态的预训练编码器上使得下游模型有更强的鲁棒性与更好的泛化能力呢。同时,本文只考虑了在分类任务上的实验,Gen-AF在更多的下游任务上是否依旧表现良好呢。
 wechat
wechat- alipay

